Gluecontext.create_Dynamic_Frame.from_Catalog
Gluecontext.create_Dynamic_Frame.from_Catalog - In your etl scripts, you can then filter on the partition columns. ```python # read data from a table in the aws glue data catalog dynamic_frame = gluecontext.create_dynamic_frame.from_catalog(database=my_database,. Gluecontext.create_dynamic_frame.from_catalog does not recursively read the data. From_catalog(frame, name_space, table_name, redshift_tmp_dir=, transformation_ctx=) writes a dynamicframe using the specified catalog database and table name. Now i need to use the same catalog timestreamcatalog when building a glue job. Datacatalogtable_node1 = gluecontext.create_dynamic_frame.from_catalog( catalog_id =. Because the partition information is stored in the data catalog, use the from_catalog api calls to include the partition columns in. With three game modes (quick match, custom games, and single player) and rich customizations — including unlockable creative frames, special effects, and emotes — every. However, in this case it is likely. Now, i try to create a dynamic dataframe with the from_catalog method in this way: Then create the dynamic frame using 'gluecontext.create_dynamic_frame.from_catalog' function and pass in bookmark keys in 'additional_options' param. Node_name = gluecontext.create_dynamic_frame.from_catalog( database=default, table_name=my_table_name, transformation_ctx=ctx_name, connection_type=postgresql. Calling the create_dynamic_frame.from_catalog is supposed to return a dynamic frame that is created using a data catalog database and table provided. We can create aws glue dynamic frame using data present in s3 or tables that exists in glue catalog. From_catalog(frame, name_space, table_name, redshift_tmp_dir=, transformation_ctx=) writes a dynamicframe using the specified catalog database and table name. # create a dynamicframe from a catalog table dynamic_frame = gluecontext.create_dynamic_frame.from_catalog(database = mydatabase, table_name =. ```python # read data from a table in the aws glue data catalog dynamic_frame = gluecontext.create_dynamic_frame.from_catalog(database=my_database,. Dynfr = gluecontext.create_dynamic_frame.from_catalog(database=test_db, table_name=test_table) dynfr is a dynamicframe, so if we want to work with spark code in. Use join to combine data from three dynamicframes from pyspark.context import sparkcontext from awsglue.context import gluecontext # create gluecontext sc =. Gluecontext.create_dynamic_frame.from_catalog does not recursively read the data. We can create aws glue dynamic frame using data present in s3 or tables that exists in glue catalog. However, in this case it is likely. ```python # read data from a table in the aws glue data catalog dynamic_frame = gluecontext.create_dynamic_frame.from_catalog(database=my_database,. Either put the data in the root of where the table is pointing to or add additional_options =.. Now, i try to create a dynamic dataframe with the from_catalog method in this way: With three game modes (quick match, custom games, and single player) and rich customizations — including unlockable creative frames, special effects, and emotes — every. Create_dynamic_frame_from_catalog(database, table_name, redshift_tmp_dir, transformation_ctx = , push_down_predicate= , additional_options = {}, catalog_id = none) returns a. Because the partition information. # create a dynamicframe from a catalog table dynamic_frame = gluecontext.create_dynamic_frame.from_catalog(database = mydatabase, table_name =. Create_dynamic_frame_from_catalog(database, table_name, redshift_tmp_dir, transformation_ctx = , push_down_predicate= , additional_options = {}, catalog_id = none) returns a. This document lists the options for improving the jdbc source query performance from aws glue dynamic frame by adding additional configuration parameters to the ‘from catalog’. Gluecontext.create_dynamic_frame.from_catalog does not. Gluecontext.create_dynamic_frame.from_catalog does not recursively read the data. Node_name = gluecontext.create_dynamic_frame.from_catalog( database=default, table_name=my_table_name, transformation_ctx=ctx_name, connection_type=postgresql. In your etl scripts, you can then filter on the partition columns. This document lists the options for improving the jdbc source query performance from aws glue dynamic frame by adding additional configuration parameters to the ‘from catalog’. With three game modes (quick match, custom games,. Now i need to use the same catalog timestreamcatalog when building a glue job. However, in this case it is likely. This document lists the options for improving the jdbc source query performance from aws glue dynamic frame by adding additional configuration parameters to the ‘from catalog’. Gluecontext.create_dynamic_frame.from_catalog does not recursively read the data. # create a dynamicframe from a. Calling the create_dynamic_frame.from_catalog is supposed to return a dynamic frame that is created using a data catalog database and table provided. ```python # read data from a table in the aws glue data catalog dynamic_frame = gluecontext.create_dynamic_frame.from_catalog(database=my_database,. From_catalog(frame, name_space, table_name, redshift_tmp_dir=, transformation_ctx=) writes a dynamicframe using the specified catalog database and table name. Gluecontext.create_dynamic_frame.from_catalog does not recursively read the data.. Dynfr = gluecontext.create_dynamic_frame.from_catalog(database=test_db, table_name=test_table) dynfr is a dynamicframe, so if we want to work with spark code in. Then create the dynamic frame using 'gluecontext.create_dynamic_frame.from_catalog' function and pass in bookmark keys in 'additional_options' param. Calling the create_dynamic_frame.from_catalog is supposed to return a dynamic frame that is created using a data catalog database and table provided. This document lists the options. ```python # read data from a table in the aws glue data catalog dynamic_frame = gluecontext.create_dynamic_frame.from_catalog(database=my_database,. In your etl scripts, you can then filter on the partition columns. In addition to that we can create dynamic frames using custom connections as well. Dynfr = gluecontext.create_dynamic_frame.from_catalog(database=test_db, table_name=test_table) dynfr is a dynamicframe, so if we want to work with spark code in.. Datacatalogtable_node1 = gluecontext.create_dynamic_frame.from_catalog( catalog_id =. This document lists the options for improving the jdbc source query performance from aws glue dynamic frame by adding additional configuration parameters to the ‘from catalog’. We can create aws glue dynamic frame using data present in s3 or tables that exists in glue catalog. # create a dynamicframe from a catalog table dynamic_frame =. Calling the create_dynamic_frame.from_catalog is supposed to return a dynamic frame that is created using a data catalog database and table provided. Then create the dynamic frame using 'gluecontext.create_dynamic_frame.from_catalog' function and pass in bookmark keys in 'additional_options' param. # create a dynamicframe from a catalog table dynamic_frame = gluecontext.create_dynamic_frame.from_catalog(database = mydatabase, table_name =. In addition to that we can create dynamic. Then create the dynamic frame using 'gluecontext.create_dynamic_frame.from_catalog' function and pass in bookmark keys in 'additional_options' param. However, in this case it is likely. Node_name = gluecontext.create_dynamic_frame.from_catalog( database=default, table_name=my_table_name, transformation_ctx=ctx_name, connection_type=postgresql. Calling the create_dynamic_frame.from_catalog is supposed to return a dynamic frame that is created using a data catalog database and table provided. Because the partition information is stored in the data catalog, use the from_catalog api calls to include the partition columns in. From_catalog(frame, name_space, table_name, redshift_tmp_dir=, transformation_ctx=) writes a dynamicframe using the specified catalog database and table name. Now i need to use the same catalog timestreamcatalog when building a glue job. With three game modes (quick match, custom games, and single player) and rich customizations — including unlockable creative frames, special effects, and emotes — every. This document lists the options for improving the jdbc source query performance from aws glue dynamic frame by adding additional configuration parameters to the ‘from catalog’. Use join to combine data from three dynamicframes from pyspark.context import sparkcontext from awsglue.context import gluecontext # create gluecontext sc =. Dynfr = gluecontext.create_dynamic_frame.from_catalog(database=test_db, table_name=test_table) dynfr is a dynamicframe, so if we want to work with spark code in. Either put the data in the root of where the table is pointing to or add additional_options =. In your etl scripts, you can then filter on the partition columns. Now, i try to create a dynamic dataframe with the from_catalog method in this way: Datacatalogtable_node1 = gluecontext.create_dynamic_frame.from_catalog( catalog_id =. Create_dynamic_frame_from_catalog(database, table_name, redshift_tmp_dir, transformation_ctx = , push_down_predicate= , additional_options = {}, catalog_id = none) returns a.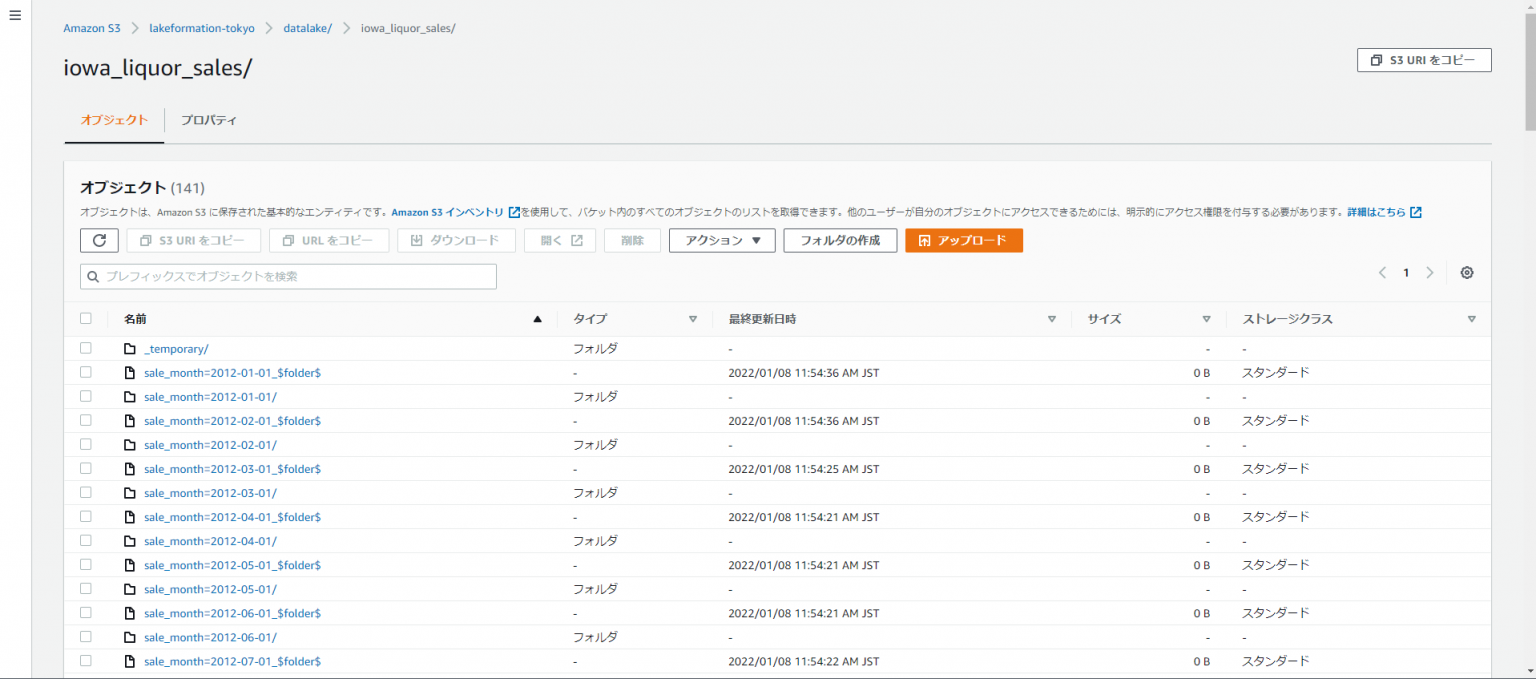
GCPの次はAWS Lake FormationとGoverned tableを試してみた(Glue Studio&Athenaも
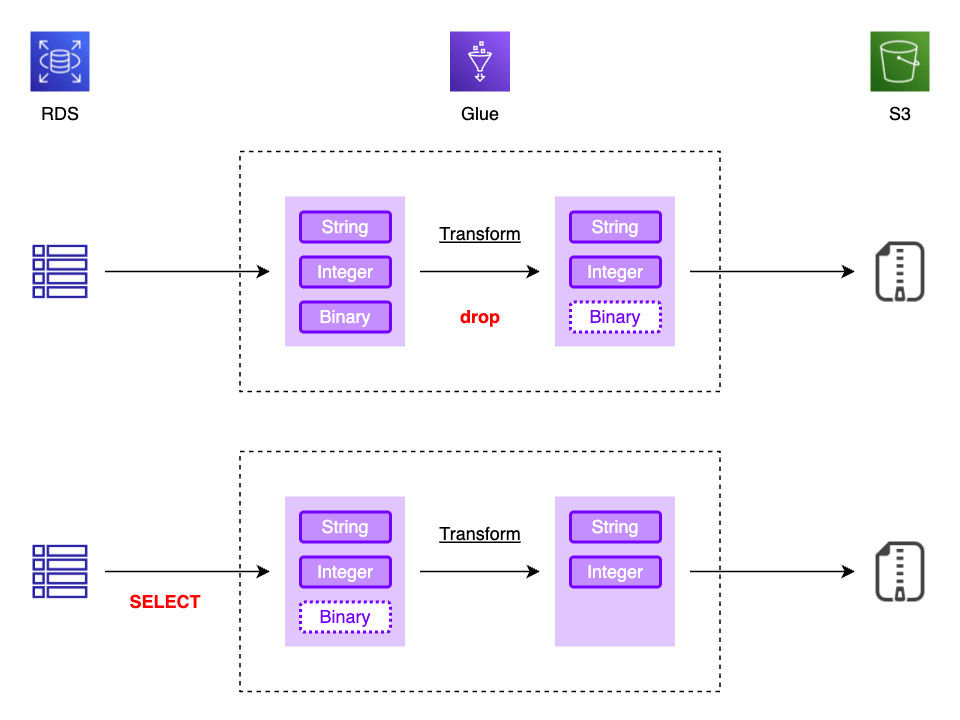
Glue DynamicFrame 生成時のカラム SELECT でパフォーマンス改善した話

AWS Glue DynamicFrameが0レコードでスキーマが取得できない場合の対策と注意点 DevelopersIO
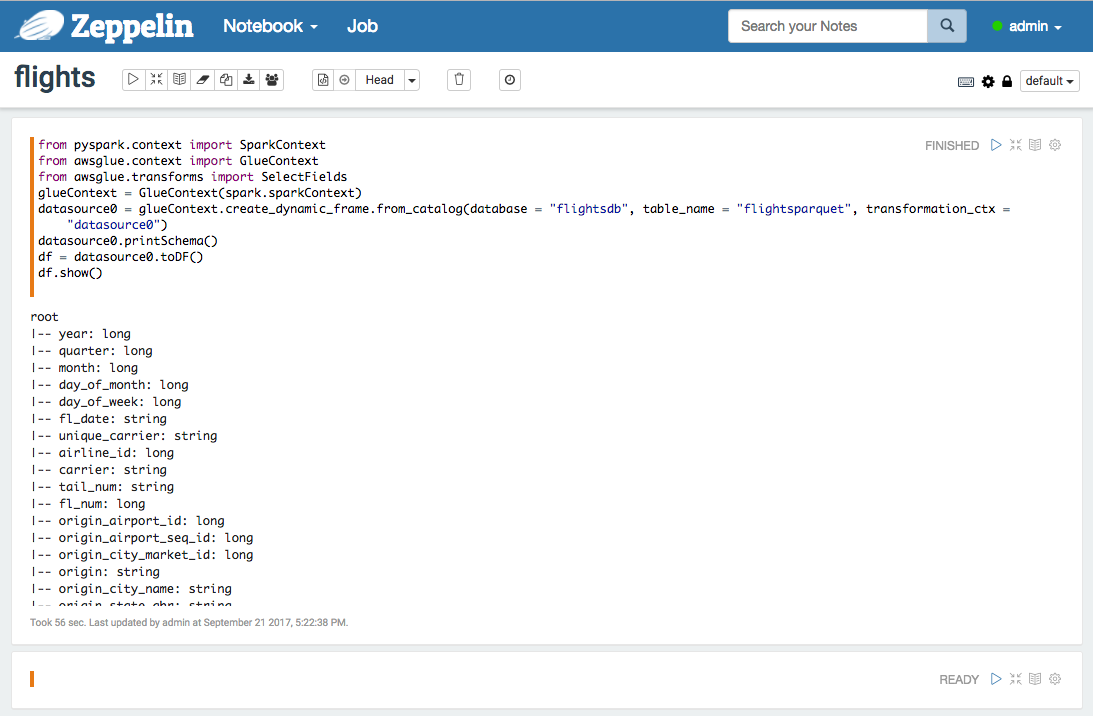
AWS Glue 実践入門:Apache Zeppelinによる Glue scripts(pyspark)の開発環境を構築する

AWS Glue create dynamic frame SQL & Hadoop

AWS 设计高可用程序架构——Glue(ETL)部署与开发_cloudformation 架构glueCSDN博客
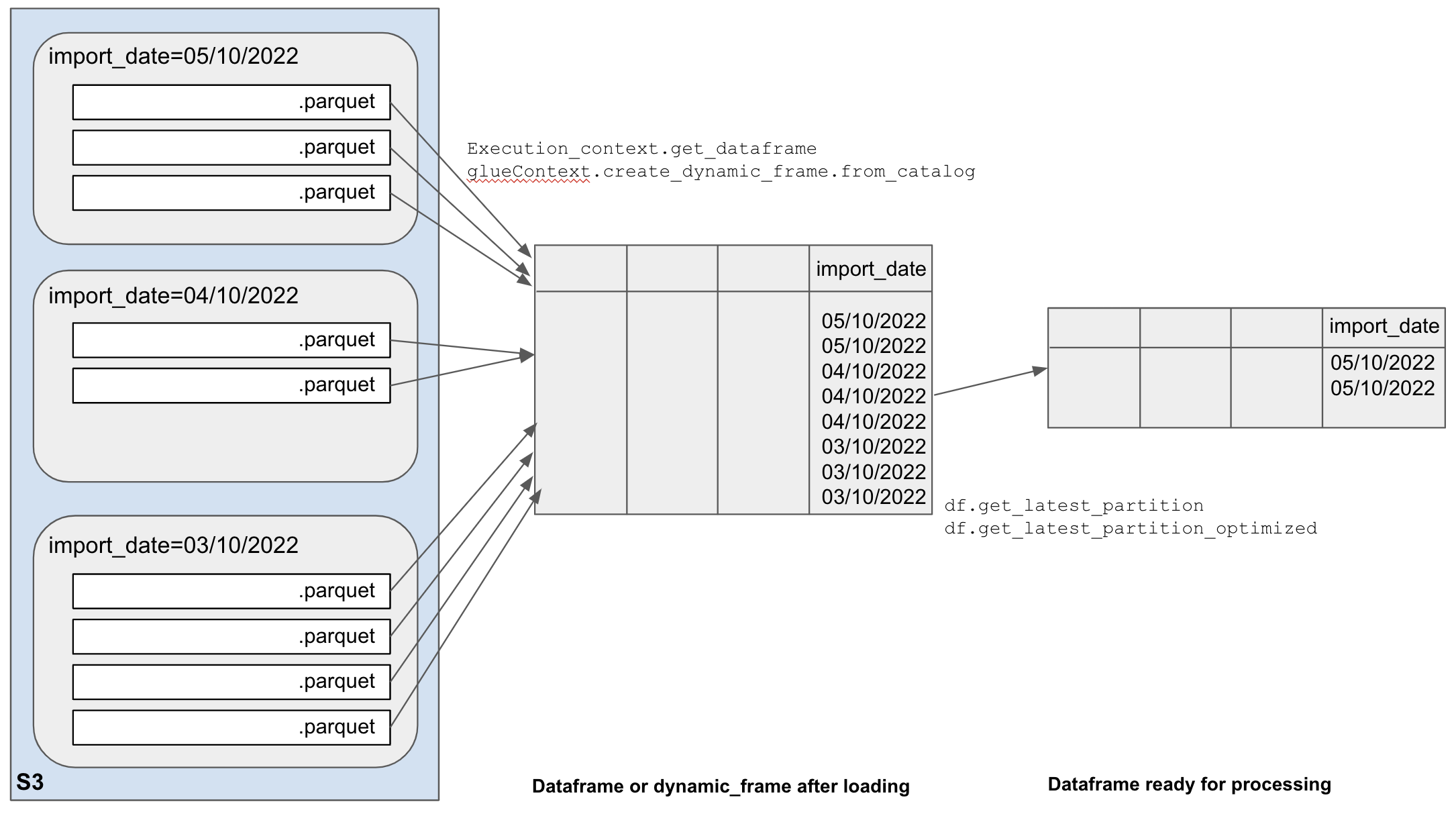
Optimizing Glue jobs Hackney Data Platform Playbook
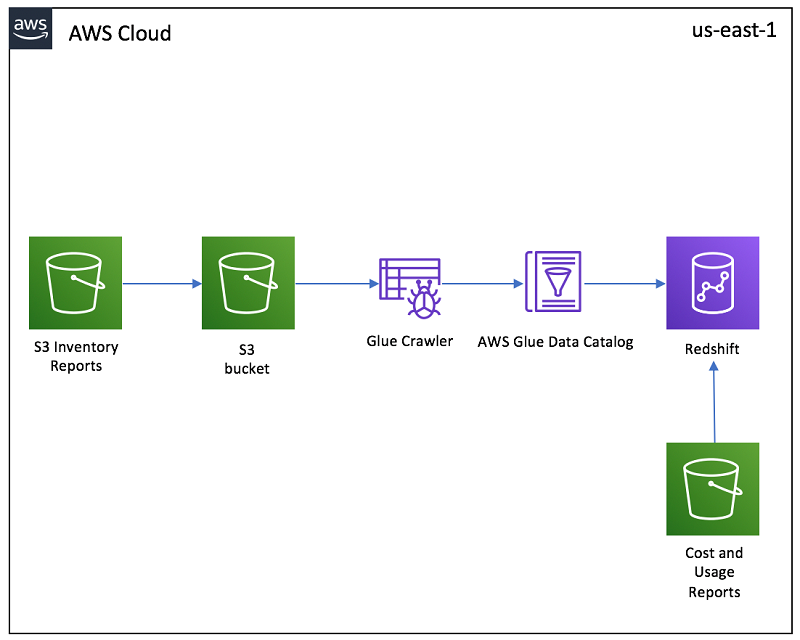
How to Connect S3 to Redshift StepbyStep Explanation
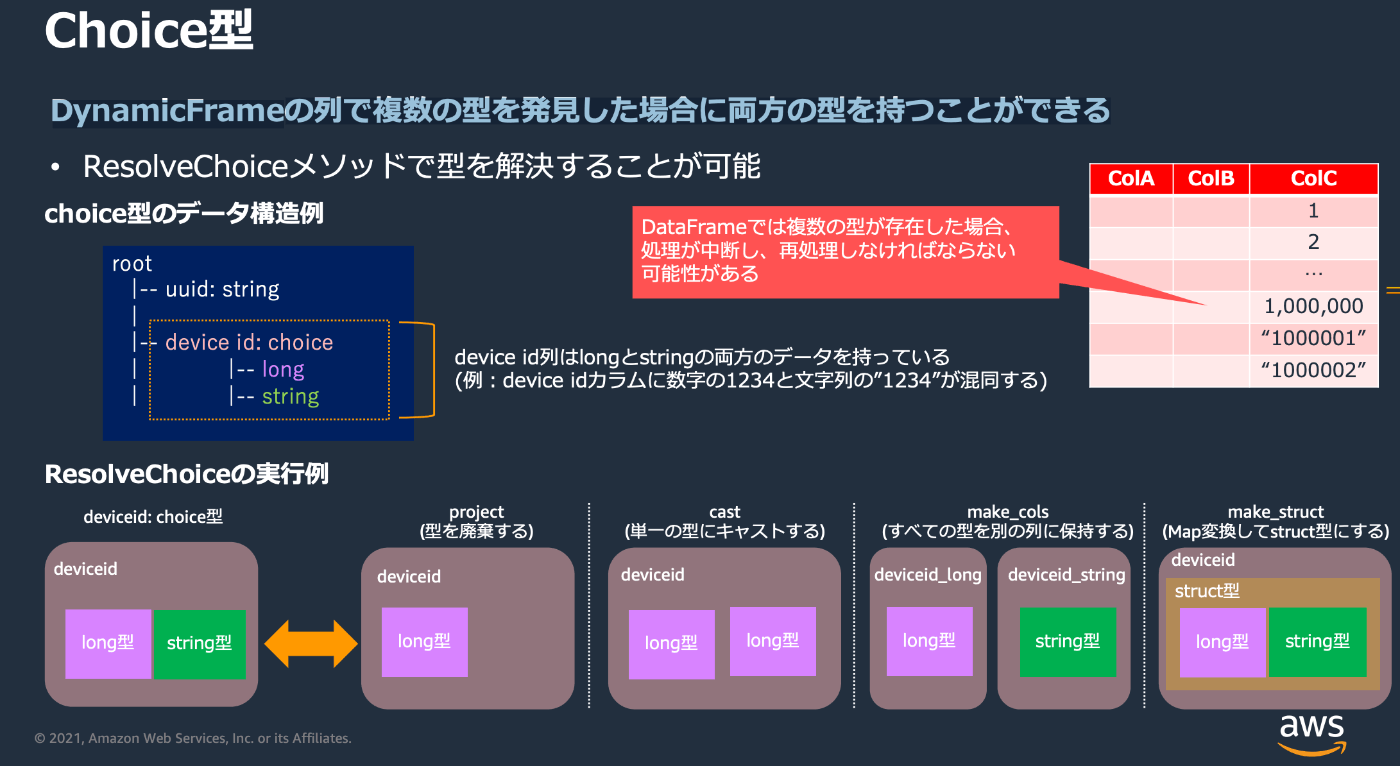
AWS Glueに入門してみた

glueContext create_dynamic_frame_from_options exclude one file? r/aws
We Can Create Aws Glue Dynamic Frame Using Data Present In S3 Or Tables That Exists In Glue Catalog.
# Create A Dynamicframe From A Catalog Table Dynamic_Frame = Gluecontext.create_Dynamic_Frame.from_Catalog(Database = Mydatabase, Table_Name =.
In Addition To That We Can Create Dynamic Frames Using Custom Connections As Well.
Gluecontext.create_Dynamic_Frame.from_Catalog Does Not Recursively Read The Data.
Related Post: